
유니세프 아동친화도시 분석 플랫폼 구축

유니세프의 아동친화도시(Child Friendly Cities) 조성을 위한 “분석 플랫폼” 프로젝트를 진행했습니다. 이번 프로젝트를 시작하기 전에 두 가지 핵심 목표를 먼저 설정했는데요. 바로 낮은 서버 비용과 안정적인 서버 운영이었습니다.
기존에 운영되던 설문조사 플랫폼의 경우 특정 시간대에 사용자 수가 몰릴 경우 서버가 다운되는 문제가 반복적으로 발생했습니다. 하지만 온디맨드(On-Demand) 방식으로 설계되어 있어 이러한 문제를 해결하기 위해서는 단순히 컴퓨팅 자원을 수직 확장하는 방법밖에 없었고, 그에 따라 운영 비용이 과도하게 증가하는 상황이었죠.
이번 통계 플랫폼에서는 이러한 구조적인 한계를 개선하고자, 비용 효율적이면서도 트래픽 변동에 유연하게 대응할 수 있는 아키텍처 설계를 우선순위에 두었습니다.
데이터 분석을 위한 설문조사 데이터 레이크 구축
데이터 분석을 하기 앞서 어떻게 오프라인 데이터와 온라인 데이터를 합칠 수 있는지 고민해 보았습니다. 전처리된 데이터는 91개의 컬럼로 이루어져 있었는데요. 초기에는 데이터베이스를 구축해서 한 테이블에 91개의 컬럼을 만들어서 몽땅 넣어버리려고 했습니다. 하지만 유지비용의 문제도 있었을 뿐더러 효율적이지 않다고 판단했어요.
다양한 방법을 모색하던 중 AWS Athena 라는 기술을 알게 되었어요. AWS Athena 는 AWS S3 에 저장되어 있는 데이터를 SQL문으로 불러올 수 있었는데, SQL 문에 있는 UNION 쿼리를 사용한다면 AWS S3 에 오프라인 데이터와 온라인 데이터를 합칠 수 있을 거라고 생각했어요. 그리고 이 방식을 사용한다면 낮은 비용으로 데이터 레이크 구축이 가능해 보였구요.
또한 S3 Dynamic Partitioning 을 사용하여 AWS S3 의 폴더 명을 key=value 형태로 지정하면 AWS Athena 에서 쿼리가 가능했어요.
SELECT * FROM "AwsDataCatalog"."database"."table"
WHERE "$path" = (
SELECT "$path"
FROM "AwsDataCatalog"."database"."table"
WHERE city = '21' AND type = 'online'
GROUP BY "$file_modified_time", "$path"
ORDER BY "$file_modified_time" DESC
LIMIT 1
)
UNION
SELECT * FROM "AwsDataCatalog"."database"."table"
WHERE "$path" = (
SELECT "$path"
FROM "AwsDataCatalog"."database"."table"
WHERE city = '21' AND type = 'offline'
GROUP BY "$file_modified_time", "$path"
ORDER BY "$file_modified_time" DESC
LIMIT 1
);이렇게 위와 같은 쿼리를 실행한다면 AWS S3 에 업로드한 온라인/오프라인 데이터를 한번에 불러오고 WHERE 문을 통해 특정 지자체의 설문조사 데이터와 가장 최근에 업로드 한 파일을 불러올 수 있어요.
온라인 설문조사 데이터를 저장하는 람다 함수 개발
온라인 설문조사 데이터의 경우 설문조사 플랫폼에 CSV 형태로 내보내는 API가 이미 존재했어요. Axios 라이브러리를 통해 API에 접근하여 CSV 파일을 AWS S3에 저장하고, 람다 함수로 만들어 배포했어요.
import Axios from "axios";
import dayjs from "dayjs";
import { S3Client, PutObjectCommand } from "@aws-sdk/client-s3";
export const handler = async (event?: any) => {
try {
const { city_id } = event.body;
const data = await Axios.post("{API URL}", {
username: "",
password: "",
});
const token: string = data.headers["authorization"];
const csv = await Axios.get(
`{API URL}/govs/${city_id}/users/csv`,
{
headers: {
Authorization: token,
},
responseType: "blob",
}
);
const s3 = new S3Client({
region: "ap-northeast-2",
});
await s3.send(
new PutObjectCommand({
Bucket: "{Bucket}",
Key: `city=${city_id}/type=online/${dayjs().format(
"YYYYMMDDHHmmss"
)}.csv`,
Body: csv.data,
})
);
return { success: true };
} catch (error) {
return { success: false };
}
};데이터 구조화를 위한 AWS Glue Table 스키마 지정
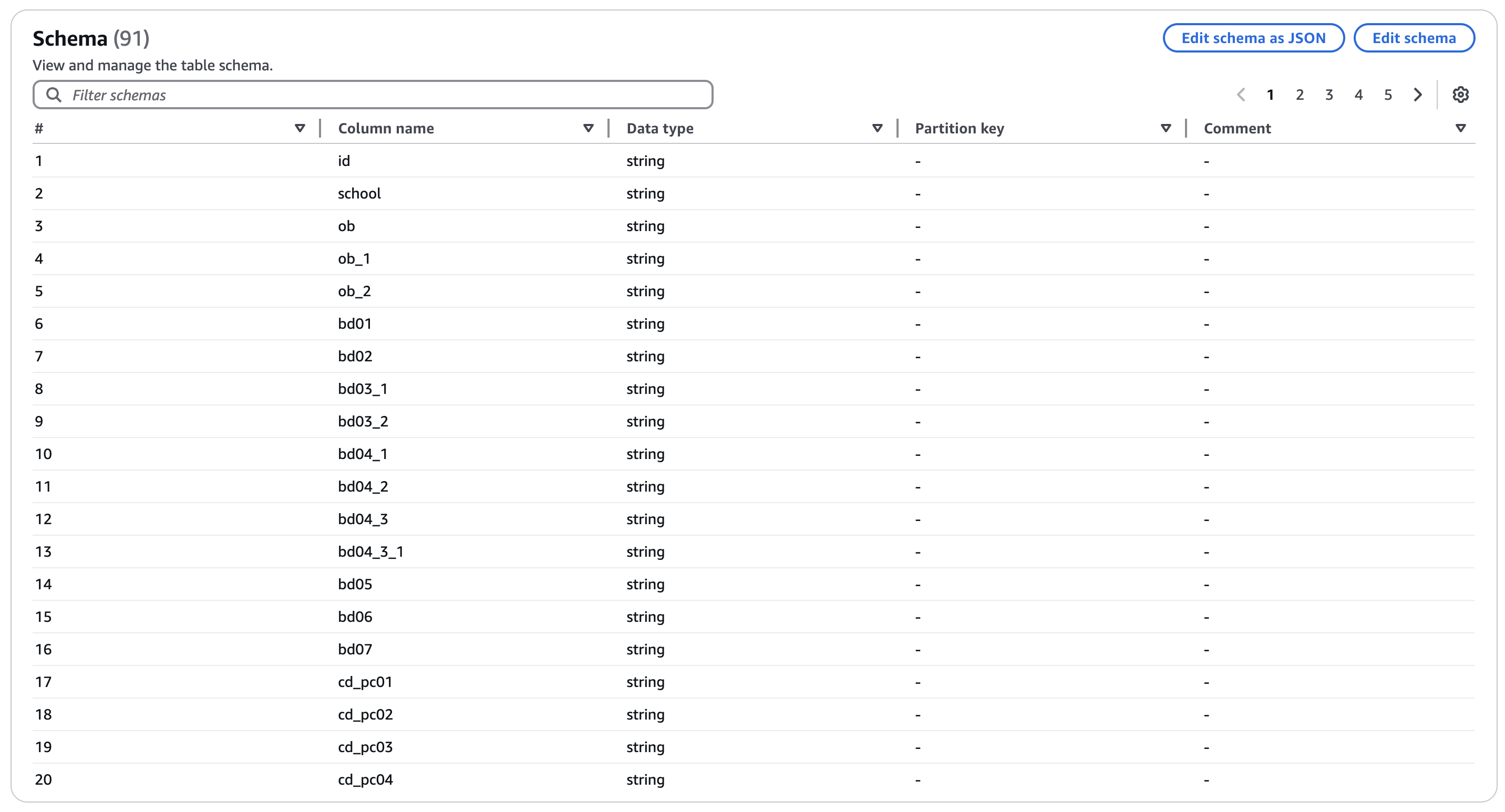
설문조사 데이터는 CSV 형태로 AWS S3 버킷에 저장되어 있지만, 이 데이터를 바로 AWS Athena 로 불러오기 위해서는 먼저 스키마를 정의해 Glue Data Catalog에 등록해야 해요. 91개의 컬럼의 스키마를 작성해 AWS Glue Data Catalog Table 를 생성했습니다.
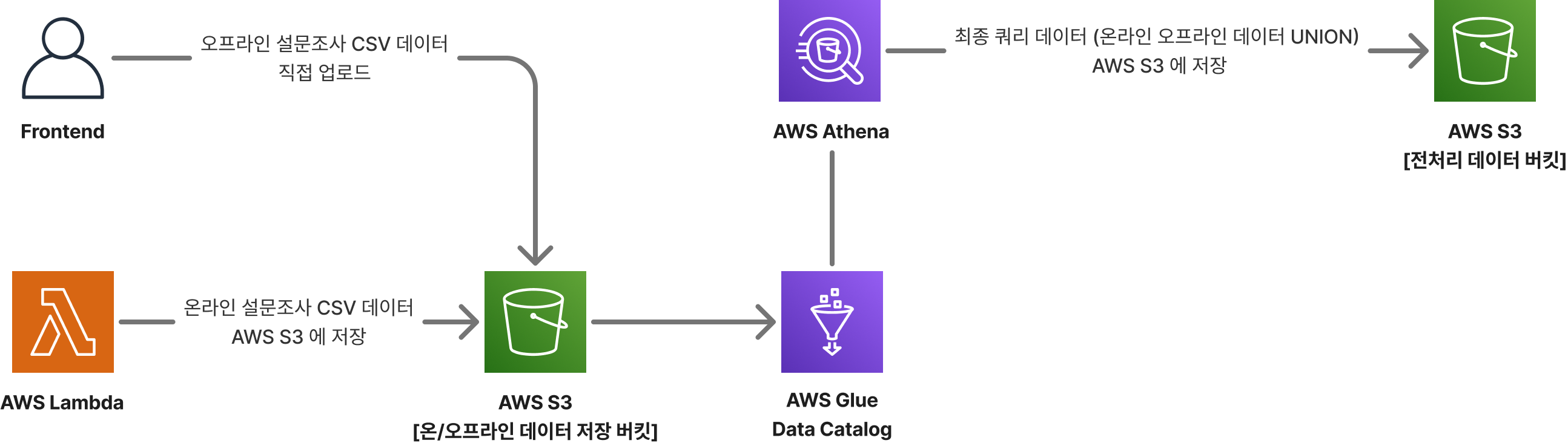
AWS Lambda 를 이용한 통계 모듈 개발
통계 분석 기능을 서버리스로 구현하려던 저희에게 가장 큰 걸림돌은 AWS Lambda의 패키지 용량 제한이었습니다. 빈도 분석, 환산점수 계산, 신뢰도 분석을 수행하기 위해 필요한 라이브러리들이 대부분 크고 무거웠기 때문에, 단순한 레이어 분리만으로는 해결이 어려웠죠.
그래서 이 문제를 풀기 위해 세 가지 방식을 검토했습니다.
- AWS Lambda 계층을 추가하는 방식 (250MB 용량 제한)
- AWS Lambda 컨테이너 이미지로 배포하는 방식 (이미지 용량 10GB 까지 배포 가능)
- AWS EFS를 AWS Lambda에 마운트하는 방식 (용량 제한 X)
초기에는 AWS EFS 방식을 선택하였지만, EFS에 라이브러리를 올리고 마운트하는 과정이 생각보다 복잡했어요. 단순히 라이브러리 파일을 업로드하는 것 이상의 작업이 필요했습니다. VPC 설정, 보안 그룹 구성 등 네트워크 설정을 세팅해 주어야 했고,AWS Lambda와 AWS EFS 간 IAM 구성도 매끄럽게 맞춰야 했어요. 무엇보다 AWS EFS에서 라이브러리를 로드할 때의 초기 지연이 저희가 기대했던 응답 속도 기준을 만족하지 못하는 경우도 있었습니다.
AWS Lambda 계층의 경우 라이브러리를 관리하기에 유용하지만, 단일 계층당 용량 제한(250MB) 으로 인해 여러 라이브러리를 포함하려면 계층을 나눠서 관리해야 하는 번거로움이 있었습니다. 이에 따라 고민 끝에, AWS Lambda 컨테이너 이미지 배포 방식으로 결정했습니다.
# ma.py
import boto3
import io
import time
s3 = boto3.client('s3', region_name="ap-northeast-2")
dynamodb = boto3.resource("dynamodb")
# 사전정의된 지자체 내부 지역/구을 반환합니다.
def predata(city):
table = dynamodb.Table("{DYNAMODB_TABLE}")
response = table.query(
KeyConditionExpression="city_id = :city_id",
ExpressionAttributeValues={
":city_id": city
}
)
return response["Items"][0]
# 온/오프라인 데이터를 쿼리(병합) 후 저장된 데이터(S3)를 불러옵니다.
def load(city, columns = ['*'], max_execution = 5):
session = boto3.Session()
s3 = boto3.client('s3')
columns_join = ', '.join(columns)
params = {
'region': 'ap-northeast-2',
'database': '{{DATABASE}}',
'catalog': 'AwsDataCatalog',
'bucket': 's3://{BUCKET}/',
'key': time.strftime('date=%Y%m%d/'),
'query': """
SELECT {} FROM "AwsDataCatalog"."{DATABASE}"."{TABLE}"
WHERE (
SELECT "$file_modified_time" as time, "$path" AS path
FROM "AwsDataCatalog"."{DATABASE}"."{TABLE}"
WHERE city = '{}' AND type = 'online'
GROUP BY "$file_modified_time", "$path"
ORDER BY "$file_modified_time" DESC LIMIT 1
).path = "$path"
UNION
SELECT {} FROM "AwsDataCatalog"."{DATABASE}"."{TABLE}"
WHERE (
SELECT "$file_modified_time" as time, "$path" AS path
FROM "AwsDataCatalog"."{DATABASE}"."{TABLE}"
WHERE city = '{}' AND type = 'offline'
GROUP BY "$file_modified_time", "$path"
ORDER BY "$file_modified_time" DESC LIMIT 1
).path = "$path";
""".format(columns_join, city, columns_join, city)
}
client = session.client('athena', region_name=params["region"])
execution = client.start_query_execution(
QueryString=params["query"],
QueryExecutionContext={
'Database': params['database'],
'Catalog': params['catalog']
},
ResultConfiguration={
'OutputLocation': params['bucket'] + params['key'],
},
ResultReuseConfiguration={
'ResultReuseByAgeConfiguration': {
'Enabled': True,
'MaxAgeInMinutes': 3
}
}
)
execution_id = execution['QueryExecutionId']
state = 'RUNNING'
while (max_execution > 0 and state in ['RUNNING', 'QUEUED']):
max_execution = max_execution - 1
response = client.get_query_execution(QueryExecutionId = execution_id)
if 'QueryExecution' in response and \
'Status' in response['QueryExecution'] and \
'State' in response['QueryExecution']['Status']:
state = response['QueryExecution']['Status']['State']
if state == 'FAILED':
return False
elif state == 'SUCCEEDED':
s3_path = response['QueryExecution']['ResultConfiguration']['OutputLocation']
bucket = params['bucket'].replace('s3://', "").replace("/", "")
key = s3_path.replace(params['bucket'], "")
object_url = f'https://{BUCKET}.s3.amazonaws.com/{key}'
s3_object = s3.get_object(Bucket=bucket, Key=key)['Body'].read()
return [object_url, io.BytesIO(s3_object)]
time.sleep(1)
return False
# app.py
import ma
import json
import pandas as pd
import statsmodels.api as sm
from numpyencoder import NumpyEncoder
import pingouin as pg
import numpy as np
from scipy.stats import pearsonr
from sklearn.preprocessing import StandardScaler
import warnings
warnings.filterwarnings('ignore')
def 전처리(city_id):
data = ma.load(city_id, ['*']) # 온/오프라인 통합 데이터 로드
config = {
**ma.predata(city_id), # 사전에 정의된 데이터 로드
"source_url": data[0]
}
df = pd.read_csv(data[1])
# 전처리 진행 (아동)
columns_list = ["bd04_2", "bd04_3", "bd04_3_1"]
df.loc[
(df['ob'].isin([1, 2, 3])), columns_list
] = df.loc[
(df['ob'].isin([1, 2, 3])), columns_list
].applymap(lambda x: 99 if pd.notna(x) else x)
# ...
def lambda_handler(event, context):
city_id = event['city_id']
if(city_id):
a = 인구학적변수에대한빈도분석(city_id)
b = 조사도구의신뢰도분석(city_id)
c = 환산점수분석(city_id)
d = 세부문항분석(city_id)
e = 표준편차분석(city_id)
f = 표준조사제출서식(city_id)
merge = { **a, **b, **c, **d, **e, **f }
ma.save(city_id, json.dumps(merge, default=str, ensure_ascii = False))
return {
"city_id": city_id,
"success": True
}
else:
return {
"success": False
}
AWS Step Functions 를 이용한 함수 통합
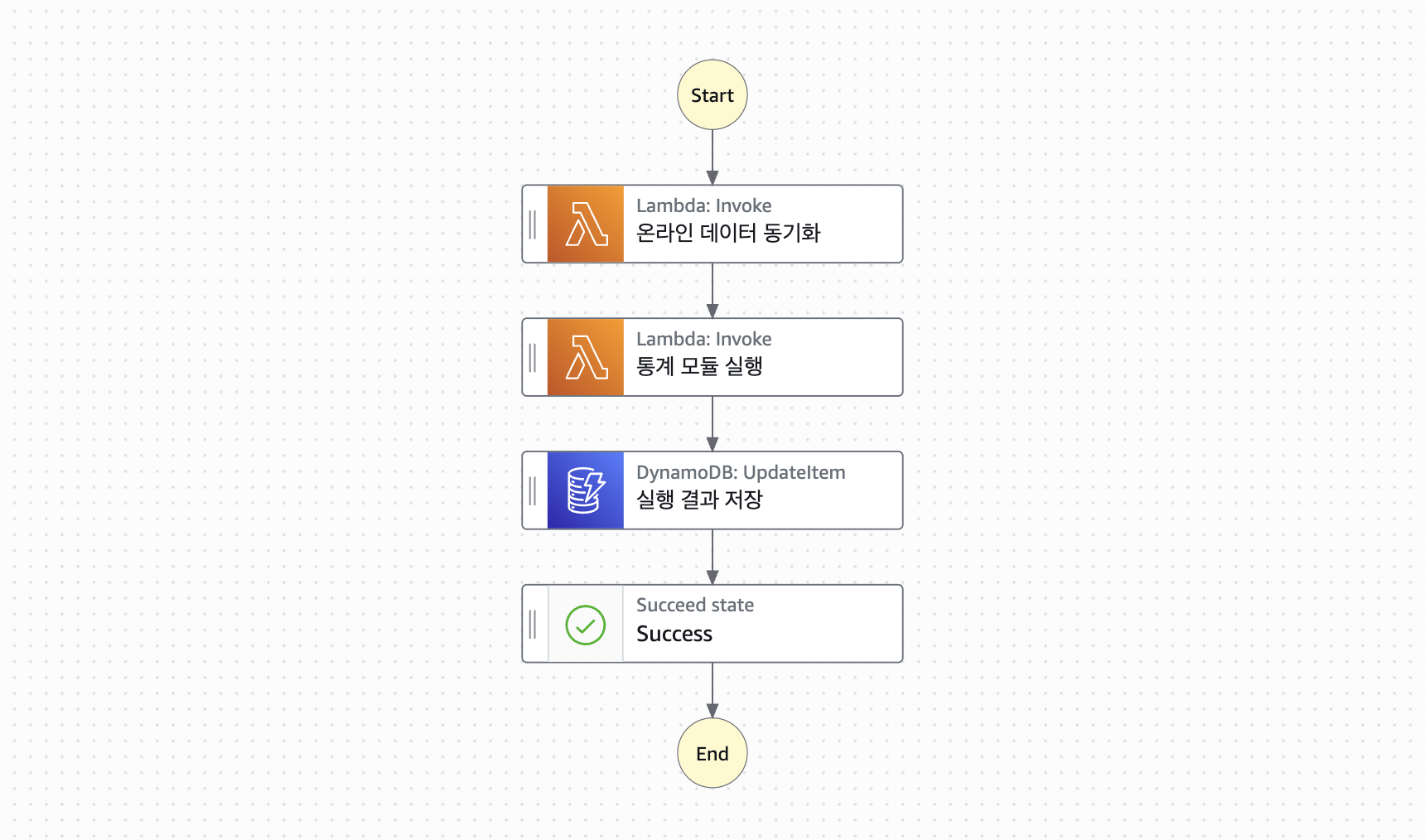
최종적인 통계 결과를 얻기 위해서는 4단계의 과정이 순차적으로 실행되어야 했는데요. 이러한 과정을 클라이언트 단에서 처리하는 데는 한계가 있었기 때문에 오케스트레이션 서비스인 AWS Step Functions 을 이용하였습니다.
AWS Step Functions 각 과정을 명확하게 구성할 수 있는 점에서 매우 효과적이었을 뿐만 아니라, 무엇보다도 비용 측면에서의 효율성이 큰 장점이었습니다. AWS 프리 티어에서는 매월 4,000건의 상태 전환(state transition) 이 무료로 제공되며, 이 프로젝트의 경우 월평균 4~5개 지자체의 데이터 분석 작업만 수행되었기 때문에, 추가 비용 없이 프리 티어 범위 내에서 충분히 운영할 수 있었습니다.
AWS Cognito 를 이용한 클라이언트 인증
통계 플랫폼의 대시보드 접근을 위해 로그인/회원가입 기능이 반드시 필요했는데요, 하지만 로그인할 사용자가 10명 미만일 뿐더러 로그인/회원가입 기능을 위해 데이터베이스를 구축하는 것은 너무 오버스팩이라고 생각하였고, 이에 따라 저희는 AWS Cognito 를 이용하여 간단하면서도 안정적인 로그인/회원가입 기능을 구현하였습니다.
AWS Cognito는 자체적으로 사용자 풀(User Pool)을 제공하고, 로그인, 회원가입, 비밀번호 관리, 토큰 발급 등 주요 기능을 기본 내장하고 있어 인프라 구성 없이도 빠르게 인증 시스템을 구축할 수 있었습니다. 또한 첫 10,000명의 유저까지 무료로 제공되었기에, 추가 비용 없이 안정적인 인증 기능을 운영할 수 있었던 점도 큰 장점이었습니다.
이후 NextJS 의 Route Handlers 기능을 이용하여 백엔드 로직을 심었습니다.
// hooks/useCognito.ts
import { useCallback, useMemo } from "react";
import {
AuthenticationDetails,
CognitoUser,
CognitoUserPool,
CognitoUserSession
} from "amazon-cognito-identity-js";
export type CognitoUserData = {
Username: string;
Password: string;
}
const useCognito = () => {
const Pool = useMemo(() => new CognitoUserPool({
UserPoolId: "{poolId}",
ClientId: "{clientId}",
}), []);
const getCognitoUser = useCallback((Username: string) => new CognitoUser({
Username,
Pool,
}), [Pool]);
const authenticateUser = useCallback(
(userdata: CognitoUserData): Promise<CognitoUserSession> => {
const user = getCognitoUser(userdata.Username);
const authDetails = new AuthenticationDetails({ ...userdata });
return new Promise((resolve, reject) => {
user.authenticateUser(authDetails, {
onSuccess: (session: CognitoUserSession) => {
resolve(session);
},
onFailure: (err) => {
reject(err);
},
});
});
},
[getCognitoUser]
);
return {
Pool,
getCognitoUser,
authenticateUser
};
}
export default useCognito;
// app/api/auth/login/route.ts
import { NextResponse } from "next/server";
import type { NextRequest as NextRequestType } from "next/server";
import {
LoginUserRequestBody,
} from "@/modules/auth/auth.dto";
import useCognito from "@/modules/hooks/useCognito";
export interface NextRequest<T = unknown> extends NextRequestType {
json: () => Promise<T>;
}
export async function POST(req: NextRequest<LoginUserRequestBody>) {
const {
authenticateUser,
} = useCognito();
const body = await req.json();
const result: NextResponse = await authenticateUser({
Username: body.username,
Password: body.password,
}).then((data) => {
const token = data.getAccessToken();
return NextResponse.json(
{
success: true,
},
{
status: 200,
headers: {
"Set-Cookie": `accessToken=${token.getJwtToken()}; SameSite=Lax; Expires=${new Date(
Date.now() + token.getExpiration()
)}; Path=/; HttpOnly;`,
},
}
)
}).catch((err) => {
switch (err.name) {
case "NotAuthorizedException":
return NextResponse.json(
{
success: false,
error_msg: err.name,
},
{
status: 400,
}
)
default:
return NextResponse.json(
{
success: false,
error_msg: err.name,
},
{
status: 409,
}
)
}
})
return result
}마무리: 서버리스를 선택하고 얻은 것들
서버리스 기반의 구조를 적용한 결과, 저희는 다음과 같은 장점을 경험할 수 있었습니다
- 낮은 비용으로 안정적인 인프라 운영
- 운영 리소스와 복잡도를 최소화하면서도 필요한 기능들을 빠르게 구현이 가능
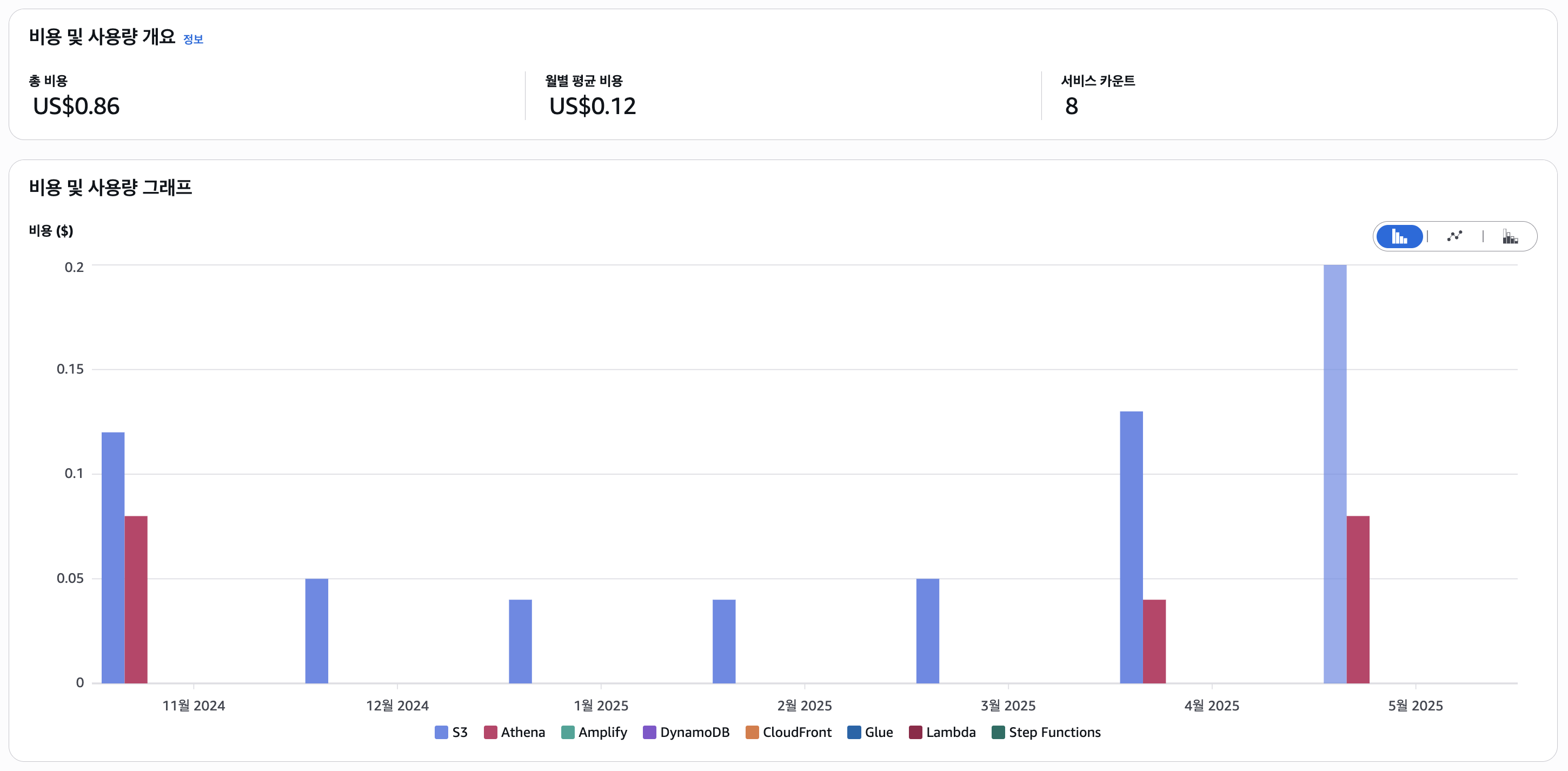
프로덕션 환경에서 7개월간 30여개의 지자체의 설문조사 데이터 분석을 진행한 결과, 월 평균 US$0.12 라는 낮은 서버 비용으로 안정적으로 운영이 가능했습니다. 하지만 장점만은 있는 것은 아니었는데요 서버리스 환경은 단순한 서버 구조의 경우 매우 효율적으로 동작하지만, 특정 기능은 서버리스의 한계로 인해 우회적인 구현 방식을 고민해야 하는 경우도 있었습니다.
그럼에도 불구하고, 이번 프로젝트의 목적과 규모, 요구사항에 있어서는 서버리스가 최적의 선택이었고, 적절한 도구를 적절한 문제에 적용했을 때 얻을 수 있는 생산성과 안정성을 직접 경험할 수 있던 소중한 기회였습니다.